Embedding, Evolution, and Validation of Spreadsheet Models in Spreadsheet Systems,
Cunha, Jácome, Fernandes João P., Mendes Jorge, and Saraiva João
, IEEE Transactions on Software Engineering, Volume 41, Issue 3, p.241-263, (2014)
AbstractThis paper proposes and validates a model-driven software engineering technique for spreadsheets. The technique that we envision builds on the embedding of spreadsheet models under a widely used spreadsheet system. This means that we enable the creation and evolution of spreadsheet models under a spreadsheet system. More precisely, we embed ClassSheets, a visual language with a syntax similar to the one offered by common spreadsheets, that was created with the aim of specifying spreadsheets. Our embedding allows models and their conforming instances to be developed under the same environment. In practice, this convenient environment enhances evolution steps at the model level while the corresponding instance is automatically co-evolved. Finally, we have designed and conducted an empirical study with human users in order to assess our technique in production environments. The results of this study are promising and suggest that productivity gains are realizable under our model-driven spreadsheet development setting.
Embedding, Evolution, and Validation of Spreadsheet Models in Spreadsheet Systems,
Cunha, Jácome, Fernandes João P., Mendes Jorge, and Saraiva João
, Number TR-HASLab:01:2014, (2014)
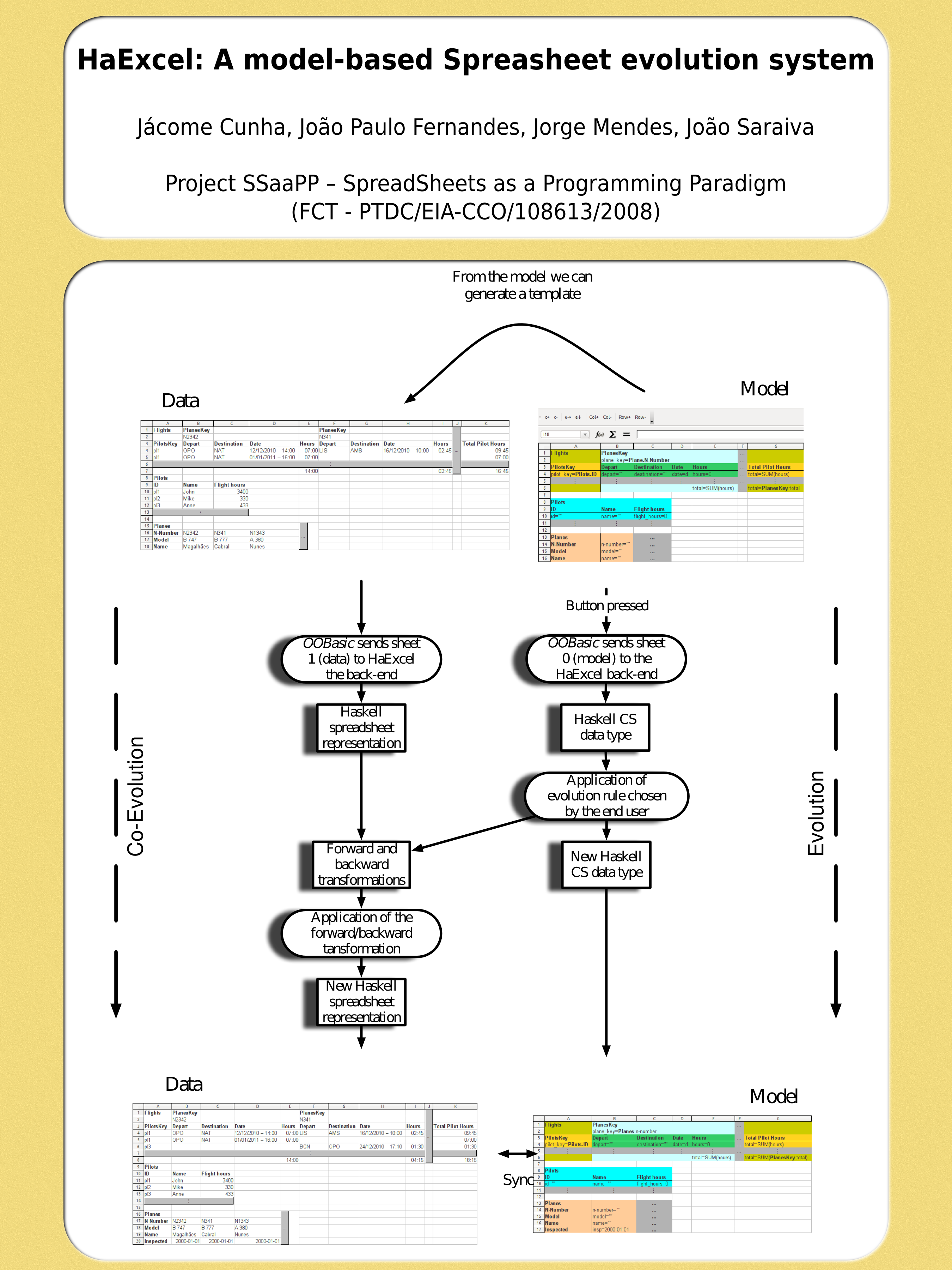
AbstractThis paper proposes and validates a model-driven software engineering technique for spreadsheets. The technique that we envision builds on the embedding of spreadsheet models under a widely used spreadsheet system, so that models and their conforming instances are developed under the same environment. In practice, this convenient environment enhances evolution steps at the model level while the corresponding instance is automatically co-evolved. Finally, we have designed and conducted an empirical study with human users in order to assess our technique in production environments. The results of this study are promising and suggest that productivity gains are realizable under our model-driven spreadsheet development setting.
ES-SQL: Visually Querying Spreadsheets,
Cunha, Jácome, Fernandes João Paulo, Mendes Jorge, Pereira Rui, and Saraiva João
, Proceedings of the 2014 IEEE Symposium on Visual Languages and Human-Centric Computing, Washington, DC, USA, p.203–204, (2014)
AbstractThis paper presents ES-SQL, an embedded tool for visually constructing queries over spreadsheets. This tool provides an expressive query environment which has knowledge on the business logic of spreadsheets, and by this knowledge it assists the user in defining the intended queries.
FaultySheet Detective: When Smells Meet Fault Localization,
Abreu, Rui, Cunha Jácome, Fernandes João Paulo, Martins Pedro, Perez Alexandre, and Saraiva João
, Proceedings of the 30th IEEE International Conference on Software Maintenance and Evolution, Washington, DC, USA, p.625–628, (2014)
AbstractThis paper presents a tool, dubbed FaultySheet Detective, for aiding in spreadsheet fault localization, which combines the detection of bad smells with a generic spectrum-based fault localization algorithm.
Graphical Querying of Model-Driven Spreadsheets,
Cunha, Jácome, Fernandes João Paulo, Pereira Rui, and Saraiva João
, Human Interface and the Management of Information. Information and Knowledge Design and Evaluation, Volume 8521, p.419–430, (2014)
AbstractThis paper presents a graphical interface to query model-driven spreadsheets, based on experience with previous work and empirical studies in querying systems, to simplify query construction for typical end-users with little to no knowledge of SQL. We briefly show our previous text based model-driven querying system. Afterwards, we detail our graphical model-driven querying interface, explaining each part of the interface and showing an example. To validate our work, we executed an empirical study, comparing our graphical querying approach to an alternative querying tool, which produced positive results.
MDSheet – Model-Driven Spreadsheets,
Cunha, Jácome, Fernandes João Paulo, Mendes Jorge, Pereira Rui, and Saraiva João
, Proceedings of the 1st Workshop on Software Engineering methods in Spreadsheets, Volume 1209, p.31–33, (2014)
AbstractThis paper showcases MDSheet, a framework aimed at improving the engineering of spreadsheets. This framework is model-driven, and has been fully integrated under a spreadsheet system. Also, its practical interest has been demonstrated by several empirical studies.
Refactoring meets Model-Driven Spreadsheet Evolution,
Cunha, Jácome, Fernandes João Paulo, Martins Pedro, Pereira Rui, and Saraiva João
, Proceedings of the 9th International Conference on the Quality of Information and Communications Technology, Quality in Model Driven Engineering Track, p.196–201, (2014)
AbstractSoftware refactoring is a well-known technique that provides transformations on software artifacts with the aim of improving their overall quality. In this paper we present a set of refactorings for ClassSheets, a modeling language that allows to specify the business logic of a spreadsheet in an object-oriented fashion. The set of refactorings that we propose allows us to improve the quality of these spreadsheet models. Moreover, it is implemented in a setting that guarantees that all model refactorings are automatically carried to all the corresponding (spreadsheet) instances, thus providing an automatic evolution of the data so it is always synchronized with the model.
Smelling Faults in Spreadsheets,
Abreu, Rui, Cunha Jácome, Fernandes João Paulo, Martins Pedro, Perez Alexandre, and Saraiva João
, Proceedings of the 30th IEEE International Conference on Software Maintenance and Evolution, Washington, DC, USA, p.111–120, (2014)
AbstractDespite being staggeringly error prone, spreadsheets are a highly flexible programming environment that is widely used in industry. In fact, spreadsheets are widely adopted for decision making, and decisions taken upon wrong (spreadsheet-based) assumptions may have serious economical impacts on businesses, among other consequences. This paper proposes a technique to automatically pinpoint potential faults in spreadsheets. It combines a catalog of spreadsheet smells that provide a first indication of a potential fault, with a generic spectrum-based fault localization strategy in order to improve (in terms of accuracy and false positive rate) on these initial results. Our technique has been implemented in a tool which helps users detecting faults. To validate the proposed technique, we consider a well-known and well-documented catalog of faulty spreadsheets. Our experiments yield two main results: we were able to distinguish between smells that can point to faulty cells from smells and those that are not capable of doing so; and we provide a technique capable of detecting a significant number of errors: two thirds of the cells labeled as faulty are in fact (documented) errors.
SSaaPP: SpreadSheets as a Programming Paradigm – Project's Final Report,
Abreu, Rui, Alves Tiago, Belo Orlando, Campos José C., Cunha Jácome, Fernandes João Paulo, Martins Pedro, Mendes Jorge, Pacheco Hugo, Peixoto Christophe, Pereira Rui, Perez Alexandre, Ribeiro Hugo, Riboira André, Saraiva João, Silva André, Silva João Carlos, and Visser Joost
, Number TR-HASLab:02:2014, (2014)
AbstractThis technical report describes the research goals and results of the SpreadSheet as a Programming Paradigm research project. This was a project funded by Funda{\c c}ão para a Ciencia e Tecnologia – FCT: the Portuguese research foundation, under reference FCOMP-01-0124-FEDER-010048, that ran from May 2010 till July 2013. This report includes the complete document reporting the results achieved during the project execution, which was submitted to FCT for evaluation on October 2013. It describes the goals of the project, and the different research tasks presenting the deliver- ables of each of them. It also presents the management and result dissemination work performed during the project's execution. The document includes also a self assess- ment of the achieved results, and a complete list of scientific publications describing the contributions of the project. Finally, this document includes the FCT evaluation report.
{kind=link}