Software refactoring is a well-known technique that provides transformations on software artifacts with the aim of improving their overall quality.
In the past, we have proposed a catalog of refactoring for spreadsheet models expressed in the ClassSheets modeling language, which allows us to specify the business logic of a spreadsheet in an object-oriented fashion.
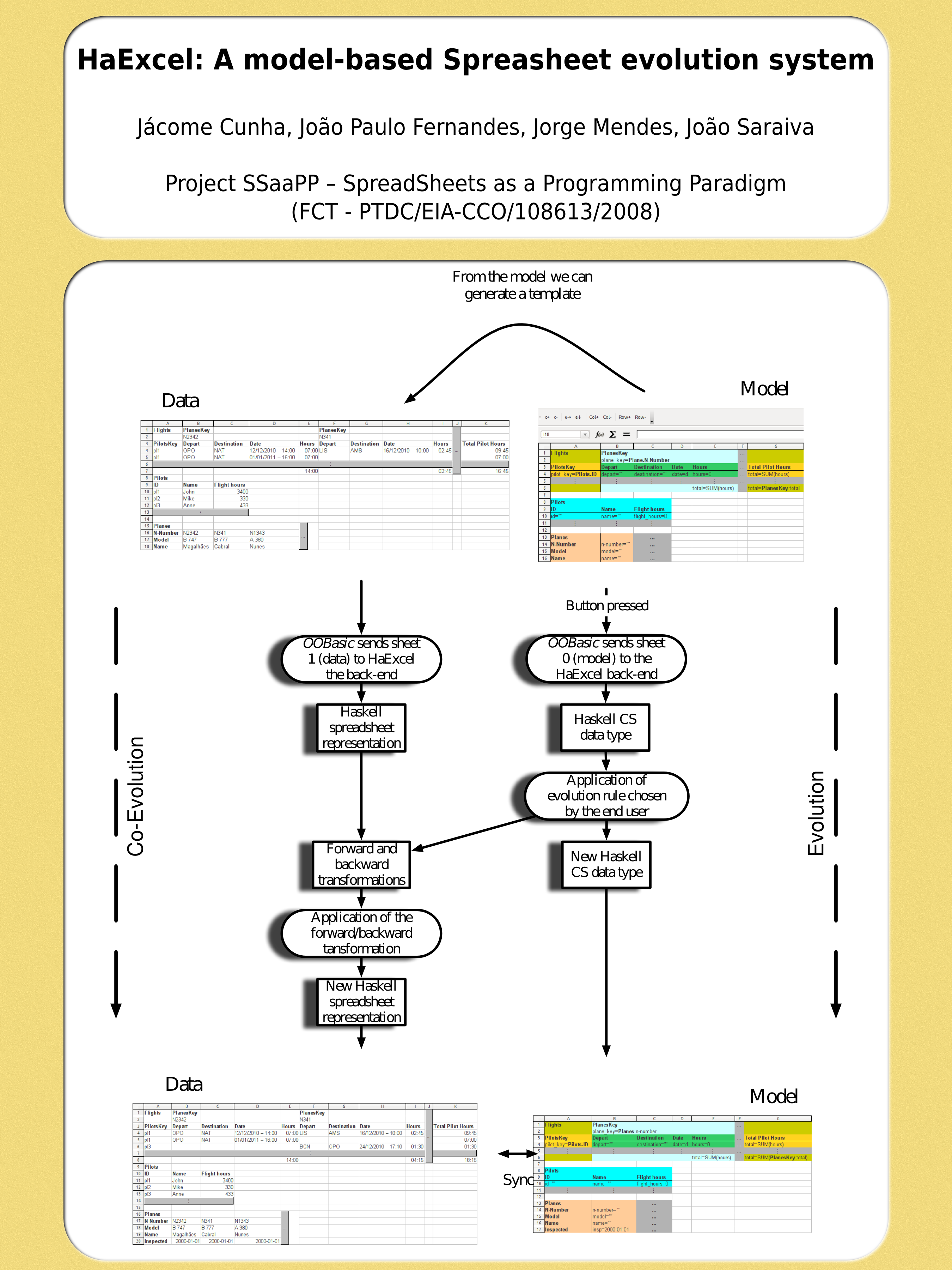
Reasoning about spreadsheets at the model level enhances a model-driven spreadsheet environment where a ClassSheet model and its conforming instance (the spreadsheet data) automatically co-evolves after a refactoring is applied at the model level. Our motivation for such research was to improve the model and its conforming instance: the spreadsheet data.
In this paper we define such refactorings using previously proposed evolution steps for models and instances.
We also present an empirical study we designed and conducted in order to confirm our original intuition that these refactorings have a positive impact on end-user productivity, both in terms of effectiveness and efficiency.
The results are presented not only in terms of productivity changes between refactored and non-refactored scenarios, but also in terms of overall user satisfaction, relevance, and experience.
In almost all cases the refactorings indeed improved end-users productivity. Moreover, in most cases users were more engaged with the refactored version of the spreadsheets they worked with.
{kind=link}