Type-Safe Evolution of Web Services,
Campinhos, João, Seco João Costa, and Cunha Jácome
, Proceedings of the 2nd International Workshop on Variability and Complexity in Software Design (VACE 2017), a ICSE workshop, Buenos Aires, Argentina, (2017)
Detecting Anomalous Energy Consumption in Android Applications,
Carção, Tiago, Couto Marco, Cunha Jácome, Fernandes João Paulo, and Saraiva João
, Proceedings of the 18th Brazilian Symposium on Programming Languages, p.77-91, (2014)
AbstractThe use of powerful mobile devices, like smartphones, tablets and laptops, are changing the way programmers develop software. While in the past the primary goal to optimize software was the run time optimization, nowadays there is a growing awareness of the need to reduce energy consumption. This paper presents a technique and a tool to detect anomalous energy consumption in Android applications, and to relate it directly with the source code of the application. We propose a dynamically calibrated model for energy consumption for the Android ecosystem, and that supports different devices. The model is then used as an API to monitor the application execution: first, we instrument the application source code so that we can relate energy consumption to the application source code; second, we use a statistical approach, based on fault-localization techniques, to localize abnormal energy consumption in the source code.
Modeling the Impact of UAVs in Sustainability,
Conejero, José, Brito Isabel, Moreira Ana, Cunha Jácome, and Araújo João
, 5th International Workshop on Requirements Engineering for Sustainable Systems (RE4SuSy) @RE16, Beijing, China, (2016)
Static Energy Consumption Analysis in Variability Systems,
Couto, Marco, Cunha Jácome, Fernandes João Paulo, Pereira Rui, and Saraiva João Alexandre
, 2nd Green in Software Engineering Workshop (GInSEng’16), an event of the 4th International Conference on ICT for Sustainability (ICT4S), 29 Aug. - 1 Sep., Amsterdam, The Netherlands, (2016)
AbstractEnergy consumption is becoming an evident concern to software developers. This is even more notorious due to the propagation of mobile devices. Such propagation of devices is also influencing software development: a software system is now developed has a set of similar products sharing common features.
In this short paper, we describe our methodology aim at static and accurately predict the energy consumption of software products in such variability systems, typically called software product lines.
Products go Green: Worst-Case Energy Consumption in Software Product Lines,
Couto, Marco, Borba Paulo, Cunha Jácome, Fernandes João P., Pereira Rui, and Saraiva João
, 21st International Systems and Software Product Line Conference, Sept 25-29, Sevilla, Spain, (2017)
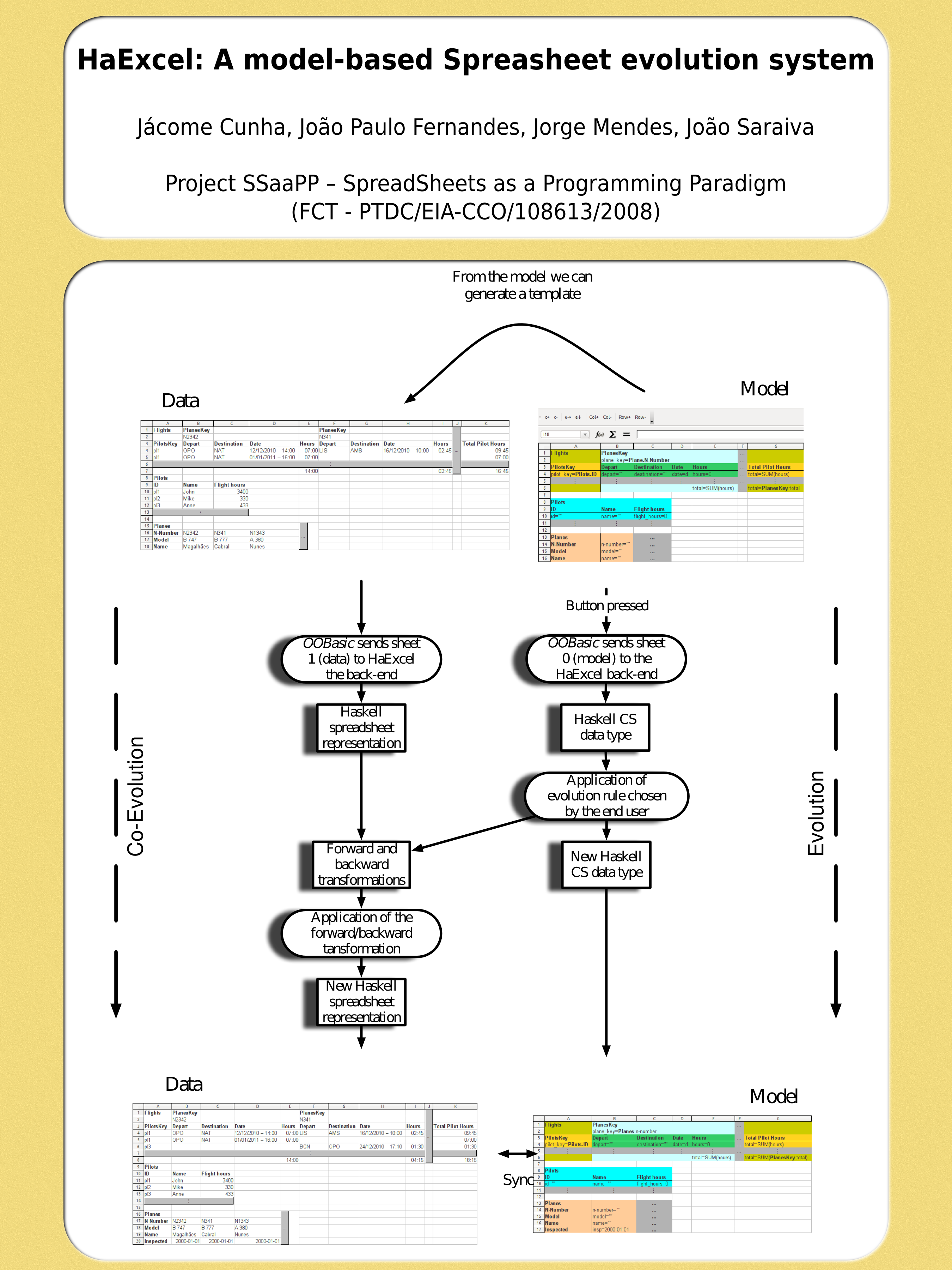
Refactoring meets Model-Driven Spreadsheet Evolution,
Cunha, Jácome, Fernandes João Paulo, Martins Pedro, Pereira Rui, and Saraiva João
, Proceedings of the 9th International Conference on the Quality of Information and Communications Technology, Quality in Model Driven Engineering Track, p.196–201, (2014)
AbstractSoftware refactoring is a well-known technique that provides transformations on software artifacts with the aim of improving their overall quality. In this paper we present a set of refactorings for ClassSheets, a modeling language that allows to specify the business logic of a spreadsheet in an object-oriented fashion. The set of refactorings that we propose allows us to improve the quality of these spreadsheet models. Moreover, it is implemented in a setting that guarantees that all model refactorings are automatically carried to all the corresponding (spreadsheet) instances, thus providing an automatic evolution of the data so it is always synchronized with the model.
Type-Safe Evolution of Spreadsheets,
Cunha, Jácome, Visser Joost, Alves Tiago, and Saraiva João
, Number DI-CCTC-10-09, (2010)
AbstractSpreadsheets are notoriously error-prone. To help avoid the introduction of errors when changing spreadsheets, models that capture the structure and inter-dependencies of spreadsheets at a conceptual level have been proposed. Thus, spreadsheet evolution can be made safe within the confines of a model. As in any other model/instance setting, evolution may not only require changes at the instance level but also at the model level. When model changes are required, the safety of instance evolution can not be guarded by the model alone. Coupled transformation of models and instances are supported by the 2LT platform and have been applied for transformation of algebraic datatypes, XML schemas, and relational database models. We have extended 2LT to spreadsheet evolution. We have designed an appropriate representation of spreadsheet models, including the fundamental notions of formulæ, references, and blocks of cells. For these models and their instances, we have designed coupled transformation rules that cover specific spreadsheet evolution steps, such as extraction of a block of cells into a separate sheet or insertion of columns in all occurrences of a repeated block of cells. Each model-level transformation rule is coupled with instance level migration rules from the source to the target model and vice versa. These coupled rules can be composed to create compound transformations at the model level that induce compound transformations at the instance level. With this approach, spreadsheet evolution can be made safe, even when model changes are involved.
Embedding, Evolution, and Validation of Spreadsheet Models in Spreadsheet Systems,
Cunha, Jácome, Fernandes João P., Mendes Jorge, and Saraiva João
, IEEE Transactions on Software Engineering, Volume 41, Issue 3, p.241-263, (2014)
AbstractThis paper proposes and validates a model-driven software engineering technique for spreadsheets. The technique that we envision builds on the embedding of spreadsheet models under a widely used spreadsheet system. This means that we enable the creation and evolution of spreadsheet models under a spreadsheet system. More precisely, we embed ClassSheets, a visual language with a syntax similar to the one offered by common spreadsheets, that was created with the aim of specifying spreadsheets. Our embedding allows models and their conforming instances to be developed under the same environment. In practice, this convenient environment enhances evolution steps at the model level while the corresponding instance is automatically co-evolved. Finally, we have designed and conducted an empirical study with human users in order to assess our technique in production environments. The results of this study are promising and suggest that productivity gains are realizable under our model-driven spreadsheet development setting.
A Bidirectional Model-driven Spreadsheet Environment (Poster/Abstract),
Cunha, Jácome, Fernandes João Paulo, Mendes Jorge, and Saraiva João
, Proceedings of the 34rd International Conference on Software Engineering, p.1443–1444, (2012)
Abstractn this extended abstract we present a bidirectional model-driven framework to develop spreadsheets. By being model driven, our approach allows to evolve a spreadsheet model and automatically have the data co-evolved. The bidirectional component achieves precisely the inverse, that is, to evolve the data and automatically obtain a new model to which the data conforms.
Embedding and Evolution of Spreadsheet Models in Spreadsheet Systems,
Cunha, Jácome, Fernandes João Paulo, Mendes Jorge, and Saraiva João
, Proceedings of the 2011 IEEE Symposium on Visual Languages and Human-Centric Computing, Washington, DC, USA, p.186–201, (2011)
AbstractThis paper describes the embedding of ClassSheet models in spreadsheet systems. ClassSheet models are well-known and describe the business logic of spreadsheet data. We embed this domain specific model representation on the (general purpose) spreadsheet system it models. By defining such an embedding, we provide end users a model-driven engineering spreadsheet developing environment. End users can interact with both the model and the spreadsheet data in the same environment. Moreover, we use advanced techniques to evolve spreadsheets and models and to have them synchronized. In this paper we present our work on extending a widely used spreadsheet system with such a model-driven spreadsheet engineering environment.
Towards a Catalog of Spreadsheet Smells,
Cunha, Jácome, Fernandes João P., Ribeiro Hugo, and Saraiva João
, Proceedings of the 12th International Conference on Computational Science and Its Applications - Volume Part IV, Berlin, Heidelberg, p.202–216, (2012)
AbstractSpreadsheets are considered to be the most widely used programming language in the world, and reports have shown that 90% of real-world spreadsheets contain errors. In this work, we try to identify spreadsheet smells, a concept adapted from software, which consists of a surface indication that usually corresponds to a deeper problem. Our smells have been integrated in a tool, and were computed for a large spreadsheet repository. Finally, the analysis of the results we obtained led to the refinement of our initial catalog.
Automatically Inferring ClassSheet Models from Spreadsheets,
Cunha, Jácome, Erwig Martin, and Saraiva João
, Proceedings of the 2010 IEEE Symposium on Visual Languages and Human-Centric Computing, Washington, DC, USA, p.93–100, (2010)
AbstractMany errors in spreadsheet formulas can be avoided if spreadsheets are built automatically from higher-level models that can encode and enforce consistency constraints. However, designing such models is time consuming and requires expertise beyond the knowledge to work with spreadsheets. Legacy spreadsheets pose a particular challenge to the approach of controlling spreadsheet evolution through higher-level models, because the need for a model might be overshadowed by two problems: (A) The benefit of creating a spreadsheet is lacking since the legacy spreadsheet already exists, and (B) existing data must be transferred into the new model-generated spreadsheet. To address these problems and to support the model-driven spreadsheet engineering approach, we have developed a tool that can automatically infer ClassSheet models from spreadsheets. To this end, we have adapted a method to infer entity/relationship models from relational database to the spreadsheets/ClassSheets realm. We have implemented our techniques in the HAEXCEL framework and integrated it with the ViTSL/Gencel spreadsheet generator, which allows the automatic generation of refactored spreadsheets from the inferred ClassSheet model. The resulting spreadsheet guides further changes and provably safeguards the spreadsheet against a large class of formula errors. The developed tool is a significant contribution to spreadsheet (reverse) engineering, because it fills an important gap and allows a promising design method (ClassSheets) to be applied to a huge collection of legacy spreadsheets with minimal effort.
ES-SQL: Visually Querying Spreadsheets,
Cunha, Jácome, Fernandes João Paulo, Mendes Jorge, Pereira Rui, and Saraiva João
, Proceedings of the 2014 IEEE Symposium on Visual Languages and Human-Centric Computing, Washington, DC, USA, p.203–204, (2014)
AbstractThis paper presents ES-SQL, an embedded tool for visually constructing queries over spreadsheets. This tool provides an expressive query environment which has knowledge on the business logic of spreadsheets, and by this knowledge it assists the user in defining the intended queries.
Graphical Querying of Model-Driven Spreadsheets,
Cunha, Jácome, Fernandes João Paulo, Pereira Rui, and Saraiva João
, Human Interface and the Management of Information. Information and Knowledge Design and Evaluation, Volume 8521, p.419–430, (2014)
AbstractThis paper presents a graphical interface to query model-driven spreadsheets, based on experience with previous work and empirical studies in querying systems, to simplify query construction for typical end-users with little to no knowledge of SQL. We briefly show our previous text based model-driven querying system. Afterwards, we detail our graphical model-driven querying interface, explaining each part of the interface and showing an example. To validate our work, we executed an empirical study, comparing our graphical querying approach to an alternative querying tool, which produced positive results.
A Quality Model for Spreadsheets,
Cunha, Jácome, Fernandes João Paulo, Peixoto Christophe, and Saraiva João
, Proceedings of the 8th International Conference on the Quality of Information and Communications Technology, Quality in ICT Evolution Track, p.231–236, (2012)
AbstractIn this paper we present a quality model for spreadsheets, based on the ISO/IEC 9126 standard that defines a generic quality model for software. To each of the software characteristics defined in the ISO/IEC 9126, we associate an equivalent spreadsheet characteristic. Then, we propose a set of spreadsheet specific metrics to assess the quality of a spreadsheet in each of the defined characteristics. In order to obtain the normal distribution of expected values for a spreadsheet in each of the metrics that we propose, we have executed them against all spreadsheets in the large and widely used EUSES spreadsheet corpus. Then, we quantify each characteristic of our quality model after computing the values of our metrics, and we define quality scores for the different ranges of values. Finally, to automate the atribution of a quality score to a given spreadsheet, according to our quality model, we have integrated the computation of the metrics it includes in both a batch and a web-based tool.
Model-Based Programming Environments for Spreadsheets,
Cunha, Jácome, Saraiva João, and Visser Joost
, Programming Languages, Volume 7554, p.117–133, (2012)
AbstractAlthough spreadsheets can be seen as a flexible programming environment, they lack some of the concepts of regular programming languages, such as structured data types. This can lead the user to edit the spreadsheet in a wrong way and perhaps cause corrupt or redundant data. We devised a method for extraction of a relational model from a spreadsheet and the subsequent embedding of the model back into the spreadsheet to create a model-based spreadsheet programming environment. The extraction algorithm is specific for spreadsheets since it considers particularities such as layout and column arrangement. The extracted model is used to generate formulas and visual elements that are then embedded in the spreadsheet helping the user to edit data in a correct way. We present preliminary experimental results from applying our approach to a sample of spreadsheets from the EUSES Spreadsheet Corpus.
Discovery-Based Edit Assistance for Spreadsheets,
Cunha, Jácome, Saraiva João, and Visser Joost
, Proceedings of the 2009 IEEE Symposium on Visual Languages and Human-Centric Computing (VL/HCC), Washington, DC, USA, p.233–237, (2009)
AbstractSpreadsheets can be viewed as a highly flexible end-users programming environment which enjoys wide-spread adoption. But spreadsheets lack many of the structured programming concepts of regular programming paradigms. In particular, the lack of data structures in spreadsheets may lead spreadsheet users to cause redundancy, loss, or corruption of data during edit actions. In this paper, we demonstrate how implicit structural properties of spreadsheet data can be exploited to offer edit assistance to spreadsheet users. Our approach is based on the discovery of functional dependencies among data items which allow automatic reconstruction of a relational database schema. From this schema, new formulas and visual objects are embedded into the spreadsheet to offer features for auto-completion, guarded deletion, and controlled insertion. Schema discovery and spreadsheet enhancement are carried out automatically in the background and do not disturb normal user experience.
{kind=link}